Khuyen TraninTowards Data ScienceSetting Up Automated Model Training Workflows with AWS S3The Open-Source Approach for Workflow Automation7 min read·Mar 18, 2024--1--1
Khuyen TraninTowards Data Science5 Steps to Transform Messy Functions into Production-Ready CodeThe Data Scientist’s Guide to Scalable and Maintainable Functions·11 min read·Jan 24, 2024--5--5
Khuyen TraninTowards Data Science6 Common Mistakes to Avoid in Data Science CodeAnd How to Overcome Them·10 min read·Dec 21, 2023--3--3
Khuyen TraninTowards Data ScienceHow to Build a Fully Automated Data Drift Detection PipelineAn Automate Guide to Detect and Handle Data Drift10 min read·Aug 1, 2023--5--5
Khuyen TraninTowards Data ScienceLoguru: Simple as Print, Flexible as LoggingThe simple logging solution for your Data Science Project·8 min read·Jul 17, 2023--3--3
Khuyen TraninTowards Data ScienceGit Deep Dive for Data ScientistsLearn Git through Real-Life Scenarios·9 min read·Jul 1, 2023--3--3
Khuyen TraninTowards Data SciencePoetry: A Better Way to Manage Python DependenciesAn in-depth comparison between Poetry, Pip, and Conda·10 min read·Jun 13, 2023--3--3
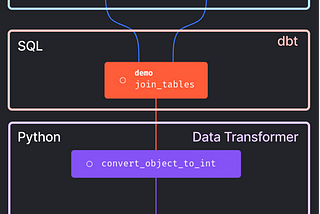
Khuyen TraninTowards Data ScienceStreamline dbt Model Development with Notebook-Style WorkspaceInteractively Build and Orchestrate Data Models·7 min read·Jun 5, 2023--1--1
Khuyen TraninTowards Data ScienceStop Hard Coding in a Data Science Project — Use Config Files InsteadAnd How to Efficiently Interact with Config Files in Python·6 min read·May 26, 2023--32--32